ChatGPT 5.5 Core Update? Changes in Query-Fanout & Citation Behavior
- vor 2 Tagen
- 2 Min. Lesezeit
Key Takeaways:

SISTRIX reported changes in ChatGPT answer behavior when switching default model from ChatGPT 5 mini to ChatGPT 5.5 calling them "ChatGPT Core Update":
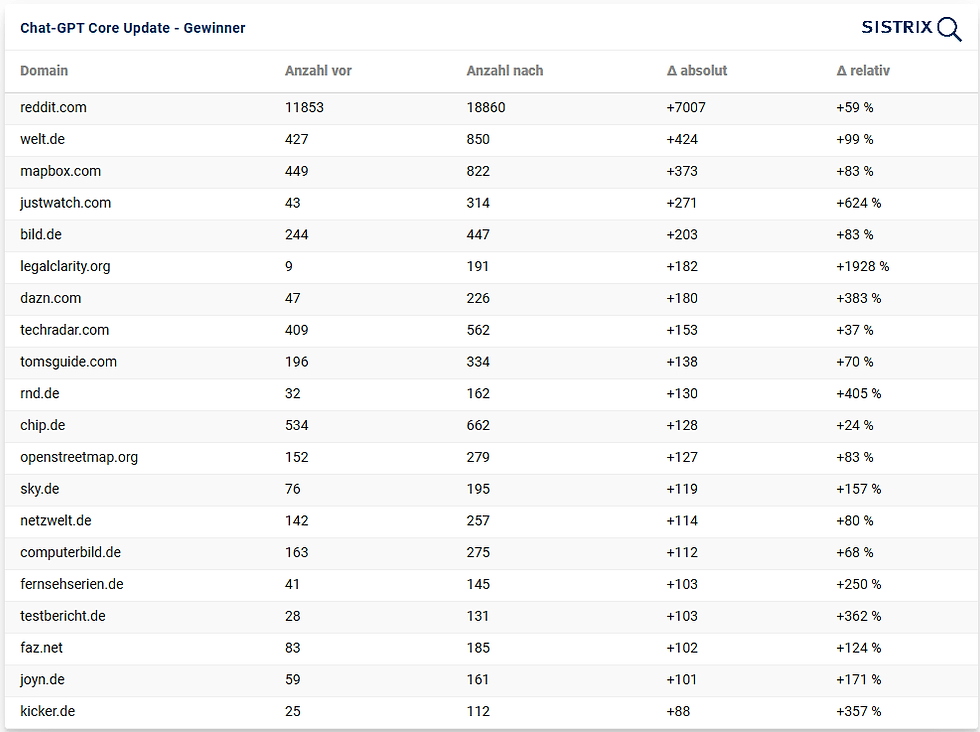
47% of cited domains changed within 48 hours in Germany
German publishers and service brands won in visibility, while international aggregator lost
Publishers Welt, FAZ, Bild, Chip, Computerbild are cited more similarly to their organic Google SEO visibility
Garg reported a surge of ChatGPT Ads of +300x: see Writesonic AI Ad Index
Yesterday, 𝟱.𝟵𝟵% of ChatGPT answers carried an ad, 1,𝟳𝟵𝟱 advertisers are now running ads on the surface
𝗪𝗵𝗲𝗿𝗲 ads are running (93.4% on US queries, Canada 5.0%, Australia 1.4%, EU at zero)
Landwehr/Konitzny (PeecAI) saw a drop in follow-up questions in ChatGPT answers with GPT 5.5 by -90%
Reynolds sees GPT 5.5 addressing the spam issue with "branded" Query Fanouts
Suganthan further analyzed ChatGPTs network activities in the browser and found:
traces of different retrieval/sourve types in the result_source:
serp: The open web baseline, mostly seen on news (Yahoo, StreetInsider)
labrador: An allowlist of established publishers. Reuters, The Guardian, the WSJ, the FT, Wikipedia, even arXiv. Snippets run to ~1,080 characters, basically full-article extracts
bright: Bright Data, a commercial web scraper. Dominant for shopping, finance, weather, local.
oxylabs: Oxylabs, a rival scraper. Regional and local press, some open web
further behavior of searching for pricing pages looking for currency/prive values and using js functions
different "levels" of being included in the answer generation:
Fetched. The model pulls your page into context. This is the result_source object. The reader never sees it.
Cited. It attaches your page as the source behind a specific sentence, the footnote you can click.
Mentioned. Your brand name appears in the answer, often as a chip linking to your site, but it isn’t the source of the claim.
On a query that overlapped my own work, ChatGPT pulled in my past conversations, with the sources listed as personal_sources: ["convo_search", "gmail", "files"].
Signs of deduplication of results per domain
Segonzac already updated his ChatGPT extension
Konitzny analyzed data from PeecAI stating that almost 50% of brand mentions are due to external websites mentioning your brand
You are mentioned based on training data
Or you are cited via third-party sources
If you are cited yourself, you’re just an extra info layer
Some measures for optimization:
monitor answer behavior - where are web searches triggered? how are sources included?
all relevant info has to be in raw html
use external sources and create coverage of your brand across multiple platforms
create a strong page per (sub)topic as their might be cannibalisation issues due to deduplication on domain level








Sources:


