Wojcik: Claude Performance decreases - Why monitoring is essential
- 21. Apr.
- 3 Min. Lesezeit

Key Takeaways:
On 16th of April, Claude Opus 4.7 was released
Wojcik cited the AMD report about performance issues with Claude Opus 4.6
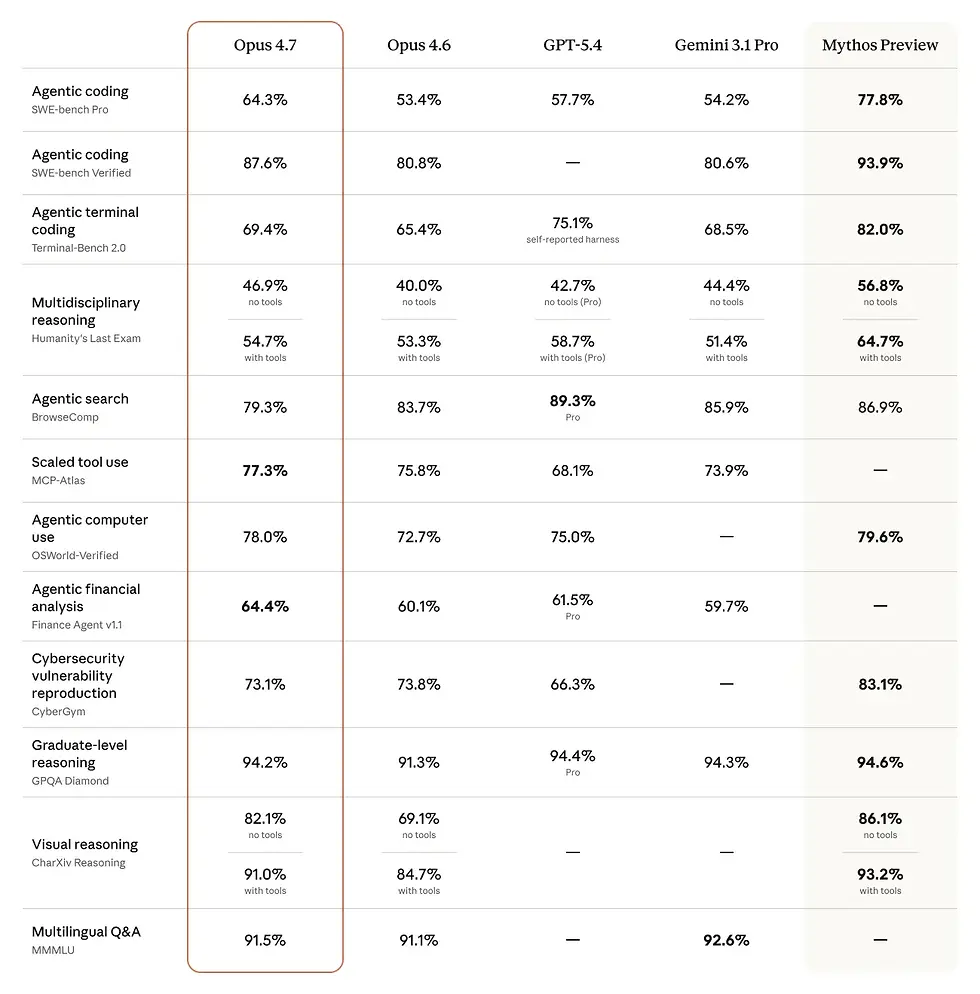
BridgeBench reported that accuracy on the hallucination benchmark of Opus 4.6 dropped to 68,3% vs. 83,3% before
He outlines that it is a natural rhythm of hype cycles that push providers to allocate infrastructure to newer models taking power away from other models
He proposes to adjust flexibly to the time of day: e.g. during end of business in the US there is a high usage - so do not run your calls between 2 and 4 pm German time.
Santiago warned that Opus 4.7 will use more token than Opus 4.6: moving your workflows/agents without proper testing might result in more token usage and thus higher costs (factor 1,00 to 1,35x reported in Opus 4.7 release message)
Schauersberger simultaneously reported performance issues and stated "Claude Code is broken"
Anthropic introduced adaptive reasoning for Opus 4.6: the model itself decides how much effort is needed, "medium" became the default
AMD reported from their analysis that Claude
reads files 70% less before editing them than before: the read vs. edit ratio dropped from 6,1 : 1 to 2,0 : 1
33,7% of changes are executed without reading files in advance
Use of "simplest" in answer increased by +642%
He proposes
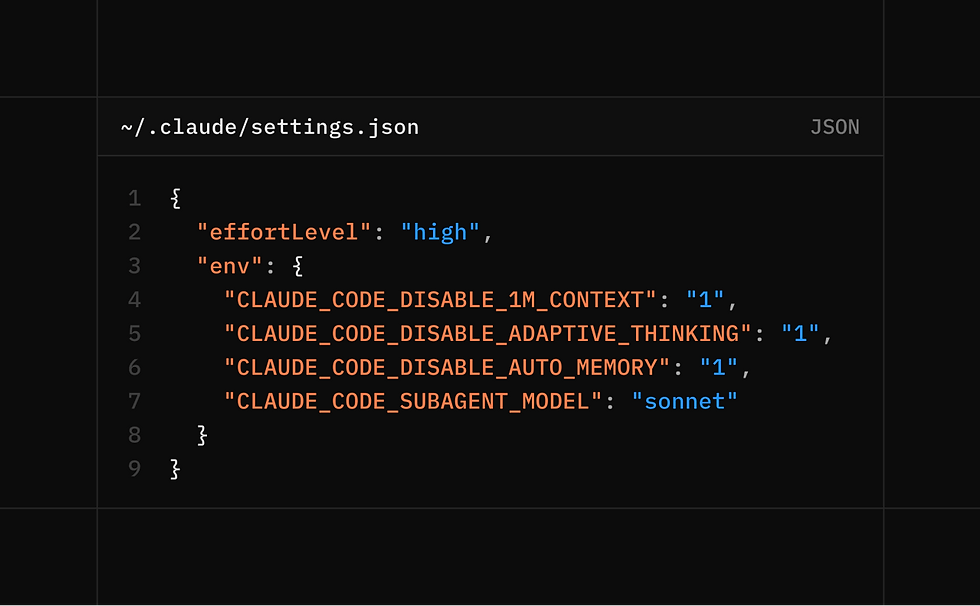
to add CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 in ~/.claude/settings.json
to put critical rules to the end of Claude.md
ensure effort_level = high/max e.g. through prompting
Others criticize that the AMD analysis is flawed and there were no broader reports about performance declines
Takeaway for your LLM assisted workflow or agentic apps
ALWAYS build automatic testing and monitoring of the outputs, to benchmark the performane over time
ALWAYS monitor token usage
ALWAYS build a flexible setup to be able to
switch prompts based on model
switch model (and prompts/workflows)
Willison compared system prompts of Opus 4.7 vs. Opus 4.6:
The child safety section has been greatly expanded, and is now wrapped in a new <critical_child_safety_instructions> tag. Of particular note: “Once Claude refuses a request for reasons of child safety, all subsequent requests in the same conversation must be approached with extreme caution.”
It looks like they’re trying to make Claude less pushy: “If a user indicates they are ready to end the conversation, Claude does not request that the user stay in the interaction or try to elicit another turn and instead respects the user’s request to stop.”
The new <acting_vs_clarifying> section includes:
When a request leaves minor details unspecified, the person typically wants Claude to make a reasonable attempt now, not to be interviewed first. Claude only asks upfront when the request is genuinely unanswerable without the missing information (e.g., it references an attachment that isn’t there).
When a tool is available that could resolve the ambiguity or supply the missing information — searching, looking up the person’s location, checking a calendar, discovering available capabilities — Claude calls the tool to try and solve the ambiguity before asking the person. Acting with tools is preferred over asking the person to do the lookup themselves.
Once Claude starts on a task, Claude sees it through to a complete answer rather than stopping partway. [...]
Before concluding Claude lacks a capability — access to the person’s location, memory, calendar, files, past conversations, or any external data — Claude calls tool_search to check whether a relevant tool is available but deferred
Claude keeps its responses focused and concise so as to avoid potentially overwhelming the user with overly-long responses. Even if an answer has disclaimers or caveats, Claude discloses them briefly and keeps the majority of its response focused on its main answer.
If people ask Claude to give a simple yes or no answer (or any other short or single word response) in response to complex or contested issues or as commentary on contested figures, Claude can decline to offer the short response and instead give a nuanced answer and explain why a short response wouldn’t be appropriate.
Claude 4.6 had a section specifically clarifying that “Donald Trump is the current president of the United States and was inaugurated on January 20, 2025”, because without that the model’s knowledge cut-off date combined with its previous knowledge that Trump falsely claimed to win the 2020 election meant it would deny he was the president. That language is gone for 4.7, reflecting the model’s new reliable knowledge cut-off date of January 2026.

Sources:


